Anatomy of Augmented Thought
There is no magic wand
Marco Giancotti,

Marco Giancotti,
Cover image:
Modified from Diehl's Anatomy for artists and students Pl.3, Conrad Diehl
People are using large language models more often and on more complex tasks than ever. Social media and marketers hammer us with the (real or dreamed-up) benefits of this uptake from all sides, but there are also voices pointing out the risks: we're told that our security is compromised, that intellectual property is undermined, and that—in case we didn't have enough already—more biases are being pushed onto us. These are all valid concerns that need to be addressed as soon as possible. But, as someone who calls himself a "thinking-tool artisan", I'm particularly concerned by two gnarly issues of generative AI:
- There isn't strong evidence of major productivity gains from AI investments in organizations. Many individuals seem to be more productive on some tasks 1 and consistently self-report saving a lot of time, but the empirical data for organizational improvements is underwhelming at best. 2345
- Several studies have shown that using LLMs a lot can lead to over-reliance and "cognitive debt", i.e. it makes people dumber. 67891011
I've seen both of these issues with my own eyes, but I also see a huge gap in our understanding of how they might come about. The scientific research on this seems to be in the Stone Age, still treating AI use as an on/off affair, asking what happens when people generically "use AI". Practitioners in software engineering, on the other hand, seem to have been teleported en masse to a distant and incomprehensible future. They've made huge strides in harnessing LLMs to write code for them—mostly via groping trial and error—but they're also caught in one hype super-tornado after the next, most people blindly copying whatever seems to work even a little for others. No one seems to be measuring how much all those techniques objectively help.
Much more research will be necessary, but I think we can already combine the little science available with the hacks that seem to be sticking, and begin to understand not just whether, but how and when to use generative AI to solve difficult tasks. If we want to export the productivity gains beyond coding and mitigate cognitive debt, we probably should figure out how this stuff works.
I think the research will eventually find that it's not mere "AI use" but proficiency in AI use, as well as the surrounding tooling, that make all the difference.
I've used LLM-enhanced tools and workflows for hours every day for a few years now, applying them to all sorts of complex problems: especially software, but also scientific research, math, learning advanced topics, product and process design, product management, and even leisure projects like dungeon-mastering and fantasy worldbuilding. These all sound like very different problem spaces, but I've found you need the same high-level skillset for all of them. The hard-earned AI lessons in software engineering can be distilled and reapplied in any other problem-solving domain. This is what this post is about.
We'll tackle the two problems above (cognitive debt and lacklustre productivity boosts) indirectly, by focusing on a third, more fundamental problem:
- We still lack a clear, powerful language to talk and think about joint human-AI problem-solving.
This is the first step toward better discussions about the other two. Perhaps if we start speaking the same language, we'll find the answers already on the tips of our tongues.
How This Post Works
What I offer here is a framework to understand what happens when someone uses a large language model to tackle a complex, difficult question or problem of any kind. I'll call it the Anatomy of Augmented Thought framework.
While researching this, the biggest realization I arrived at is that even more so than critical thinking, it is metacognition that matters when you want to use AI without falling into its many pitfalls 12. "Thinking about thinking" has always been a neat skill to practice, but in the past it has been easy to brush it off as something philosophers and a certain group of psychologists did. By the time you finish reading this post, I hope you'll be thoroughly convinced that the times have changed: we all have to become expert meta-thinkers if we are to actually reap the benefits of AI's advances.
To give some order to the fuzzy idea of "thinking", I'll borrow three simple frameworks from psychology and combine them into a larger, more detailed one composed of nine thinking categories. Then I'll consider the major factors that determine when and how we delegate things:
- How tiresome is each category of thinking?
- How much time does a thought take with and without AI?
- How does expertise interact with AI use?
Mental fatigue matters a lot, because people tend to want to skip or delegate the tasks that would tire them out the most; time spent on a task is considered the key metric of productivity; and expertise matters because it drastically changes how you guide AI and evaluate its outputs.
Each of the nine thinking categories has different implications for these three factors. The structure that emerges adds nuance to this topic, and demolishes the naïve conception of thought as a single, monolithic activity. Instead, thought is highly complex, and the way it interacts with "external thinking machines" like LLMs must be equally sophisticated.

It's very tempting to treat a state-of-the-art LLM as a magic wand: you only have to want it, pronounce a couple dozen magic words, and it will somehow make it happen for you. I'll call this the Magic Wand Illusion, and I'll make the point that it couldn't be farther from the truth. The ideal way to divide work between a human and an LLM is a mixture of human-only work, AI-only work, and work requiring the close cooperation of both.
The Magic Wand Illusion is dispelled with the Anti-Magic Effect: unlike magic, using LLMs well for complex tasks is a difficult job in itself. I'll also try to sketch what an "optimal" engagement with AI would look like for different kinds of people and different tasks.
Disclaimers
You can skip directly to the next section, or read the answers to any of these legitimate fine-print questions. You can find even more caveats and assumptions in Appendix II.
(Click on "read" next to the questions you have to show the answers.)
Is this post scientifically rigorous?
I've strived to do as rigorous and objective a job as possible, which is why the text contains references to academic papers and other more or less reputable sources. But that's not saying very much, because the science on this is full of gaps and I've had to rely on my own personal experience and insights in several places, which is N=1. This is first and foremost my subjective interpretation of these ideas, and it might be wrong on many fronts.
Still, I've spent far more time cross-checking that my insights and deductions are supported—or at least not strongly contradicted—by whatever science and expert knowledge exists about these topics than I've spent writing them, so I hope you'll at least give them the benefit of the doubt. The real value I'm aiming for may not be in the detailed takeaways (many of which are already known at least to some experts anyway) but in the clarity of the distinctions. Again, a shared language or framing.
Is this post written by AI?
Except those clearly advertised as AI-written, I've typed every single word of this post with my own meat-and-bone fingers, based on ideas that originated in my wetware (yes, I do use em-dashes regularly in my writing—I won't let LLMs take the monopoly!).
This post is not AI-written under any definition of the term, because I don't believe an AI could write it better than I can yet (at least on the metrics I care about).
That said, I did use an LLM (mainly Anthropic Claude Opus) extensively for the research and fact-checking, and throughout the long process of formulating, vetting, structuring, and organizing my thoughts. In doing so, I applied all of the notions and methods that I'm writing about (it's all very meta). In that sense, if you find what I wrote convincing (or not), you can count that fact itself as one more point in favor (or against) it.
Where is the practical advice?
This post is all about what augmented thought is: its parts and types, the various tradeoffs and risks, etc. The matter of how to think well and safely with an LLM—the methods I've adapted and extrapolated over the years—is the topic of future posts on this blog.
Table of Contents
- How This Post Works
- Disclaimers
- 📍 You are here
- Part 1: Drawing the Boundaries
- Part 2: Augment
- Conclusions
- Appendix I: Pitfall Recap
- Appendix II: Caveats and Assumptions
- Comments
- References
Part 1: Drawing the Boundaries
Cognition in 3D
Our starting point is the rejection of the lazy all-or-nothing framing of AI-augmented thought: it is probably not true that using AI is always bad for productivity, or always bad for your brain's sharpness. So what we need to figure out is when is it bad, and when okay.
In other words, we need to open up the black box we call "thought" and distinguish some subtypes by drawing new boundaries inside it in a way that is meaningful for our purpose.
There are various ways to cut up "thought", and more than one may do the job. I've settled for a three-dimensional division based on a few scientific theories, which works nicely. It is formed by three axes: the Mode axis distinguishes thoughts by their function, the Level axis is about the target of cognition, and the Phase axis separates thoughts by when they happen.
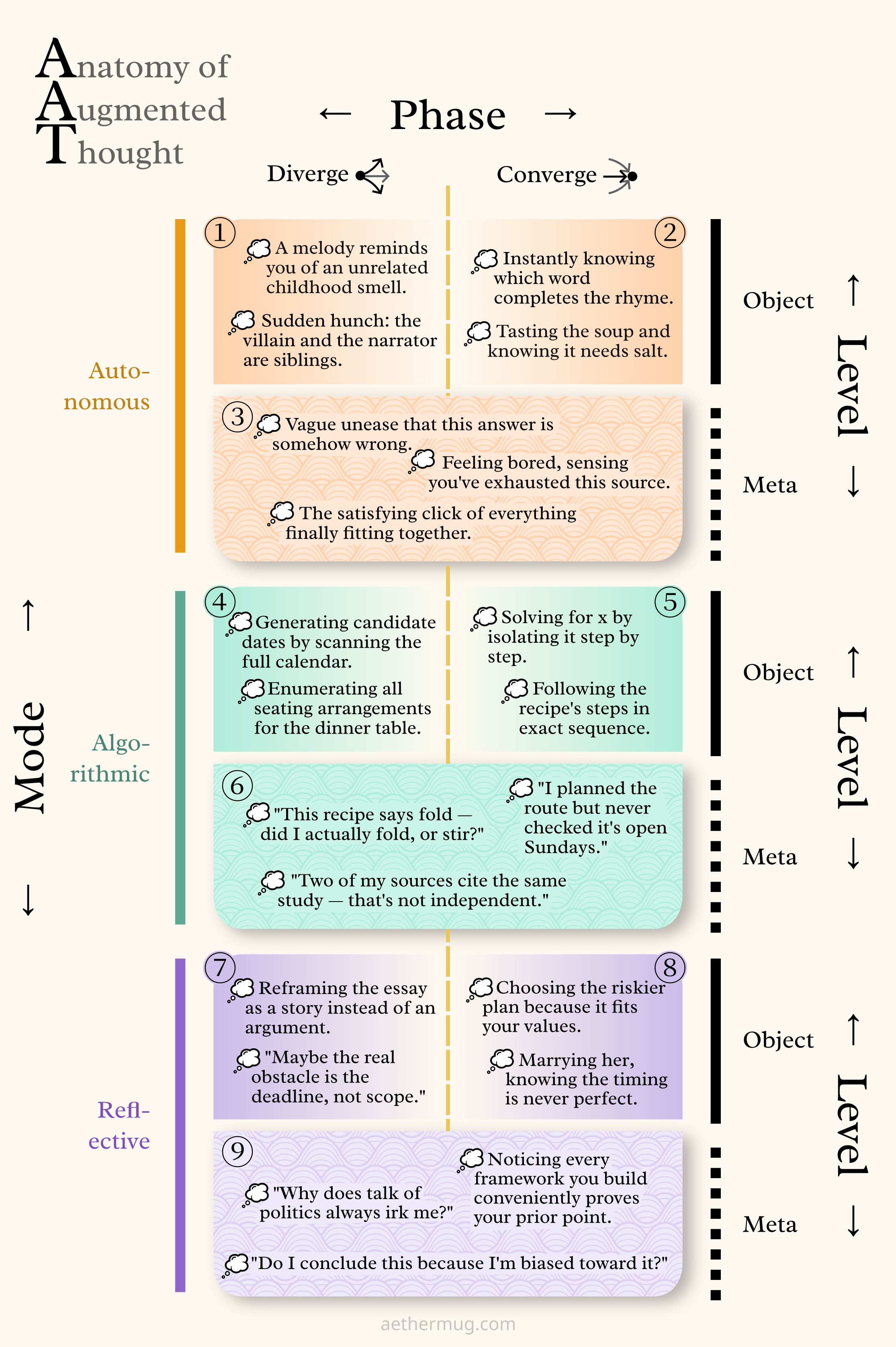
Mode Axis: Stanovich's Tripartite Mind
The dual-process theory of cognition—popularized by Nobel laureate Daniel Kahneman in Thinking, Fast and Slow—says the mind has two modes of operation, System 1 and System 2, that work quite differently: the former is quick and instinctive, while the latter is slow and rational. Keith Stanovich built on that to add a further division within System 2, effectively bringing the number of "minds" to three 13:
- The autonomous mind is largely equivalent to Kahneman's System 1, i.e. it is about pattern recognition, instinctive associations, and heuristics.
- The algorithmic mind is raw computation: following logical steps, applying predefined rules (for example mathematical rules) in sequence to arrive at a desired answer.
- The reflective mind thinks about collecting information, chooses strategies, sets and updates goals, and so on. It's the control layer, the how rather than the what.
Is this the best way to distinguish types of thinking? Maybe not, and the topic is still debated among experts. But it is a very defensible theory as of now, and (most importantly) it works extremely well for the specific case of human-LLM thinking I want to tackle. Stanovich split System 2 into algorithmic and reflective because he wanted to explain why smart people can still do dumb things—he called this dysrationalia: you can be very good at algorithmic thinking but bad at reflecting on whether what you're doing makes sense. I think this boundary is especially illuminating when it comes to language models.
I'll begin by drawing this first axis on our map.
, Algorithmic (teal), and Reflective (purple)")
Level Axis: Object and Meta
The next dimension of thought concerns the realm the thought is interested in, of which there are two possibilities: object and meta 14.
Object-level (or first-order) thinking is concerned with the actual problem at hand—it's the most obvious interpretation of the phrase "thinking about something", so no surprise there. Meta-level (or second-order) thinking, also called metacognition, on the other hand, is thinking about the thinking process itself. A couple of examples might help here.
Suppose you're trying to solve a crossword puzzle:
- object-level cognition means thinking about the hints and the word candidates;
- meta-level cognition is thinking things like "am I focusing too much on this word?" or "things aren't adding up, I might have written the wrong word somewhere."
If, instead, the problem you're tackling is climate change:
- interpreting scientific measurements and considering possible mitigation actions is mostly object-level thinking;
- monitoring your success in solving climate change and wondering about how to best communicate the problem to others are examples of meta-level thinking.
Like the others, this distinction will prove critical to understanding how best to delegate tasks to an LLM. On the map, I'll show it as a splitting of each mode of thought in two: each mode can be focused at the object level or at the meta level.
 is split into two cells — Object (solid fill) and Meta (patterned fill)")
Here you might be wondering what the difference is between metacognition and Stanovich's reflective mind. In a colloquial sense, reflective thought is itself "meta", because it's about strategies and self-correction. But the "meta" level in the object-meta axis is even more meta than that!
One way to remember the difference is that reflective thoughts are about how to do something well, while meta-level thoughts are about you doing things. The focus is external in the former case, self-referential in the latter.
You can think both object-level reflective thoughts and meta-level reflective thoughts, and soon we'll see how that distinction matters. The difference should become clear once you read some more examples.
Phase Axis: Divergent and Convergent Thinking
This third way to divide cognition is concerned with the natural lifecycle of thought: you first need to diverge (search and explore many possible directions and approaches) before you can converge (prune the list of possibilities, discard the bad ones, whittle them all down until you reach a single output).
This theory was first proposed by J. P. Guilford in 1967 1516, but even today you'll find it in most business courses on management and design (the design thinking framework has it as one of its tenets 17).
Divergent thinking is largely about creativity, because it implies coming up with novel ideas and yet-unverified paths to your goal. It tends to be messy and noisy, because the goal of this phase is to expand your range, not to bring clarity. It relies on the brain's default mode network (DMN)18.
Convergent thinking, on the other hand, is all about bringing structure, removing the errors and the unnecessary fluff, and selecting the best option—a job for the regulation skills of executive-control neural networks.
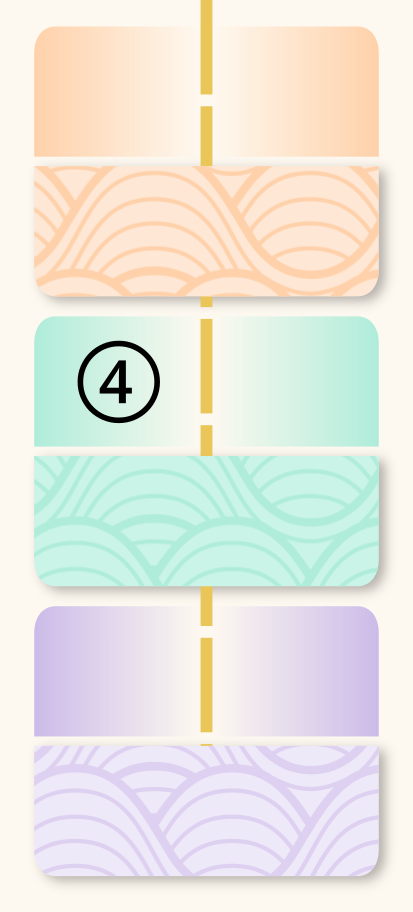
Normally, adding this third axis would mean splitting every one of the 6 existing categories (3 for Mode times 2 for Level) into two, leading to 6 ✕ 2 = 12 categories. But I've found that metacognition doesn't really need a distinction between convergent and divergent thought. That seems to be mostly relevant to object-level thoughts, which usually involve an exploration of what's “out there” before drawing conclusions. At the meta level, there is no “out there”, and separating divergent and convergent processes, while arguably possible, doesn't offer much insight. So I'll avoid making that distinction for metacognition, leaving us with 9 different categories of thought.
 is divided horizontally into Object (solid fill, top) and Meta (patterned fill, bottom); a dashed vertical line further divides each Object section into Diverge (left) and Converge (right) halves; Meta sections remain undivided, yielding nine total cells")
Putting Them Together: the AAT Framework
With these three axes, we get a grid of nine thought categories. To keep the terms short, in this post I'll omit mentioning the word "object" in the names of object-level thinking categories. Unless I write "meta-", you should assume I'm talking about the good ol' object level. I will also shorten "autonomous" to "auto" and "algorithmic" to "algo".
This is the Anatomy of Augmented Thought (AAT) framework.
, Auto-Convergent (2), Meta-Autonomous (3), Algo-Divergent (4), Algo-Convergent (5), Meta-Algorithmic (6), Reflective-Divergent (7), Reflective-Convergent (8), Meta-Reflective (9)")
All nine thinking categories are useful for something, and—with the exception of diverge → converge—there is no predefined order in which you use (or should use) them. All can happen more or less simultaneously and in loops, and you shift your attention from one to another very quickly whenever you're actively thinking.
But there is one pattern that seems absolutely unavoidable in complex problem solving: no matter what paths you weave on the AAT grid, you must periodically make decisions that bring you closer to the solution, be they object-level decisions on direct actions (writing a word in the crossword puzzle) or meta-level indirect actions (resolving to ask your friend for help with the puzzle).
Every thinking process, then, is a tangle of many types of thinking dotted with decision points.
Pre-Augmentation Anatomy of Thought
Before we can stick the "Augmented" on and say anything useful about LLMs, we need to understand some things about the plain Anatomy of Thought, unaided by technology. Below you can read (AI-sourced) examples and (my own) clarifications about each of the nine types of thought in the AAT framework.
Throughout the rest of this post, every mention of one of these categories is followed by an ⓘ icon. Click it to jump to that category's definition below; use the browser's "back" button ⇦ to return to your original reading position.
1. Auto-Divergent
Object-level autonomous divergent thought

What it is
Representative examples of auto-divergent thoughts are associative leaps, pattern recognition, and remote connections.
It's the hunches you have—often suddenly and unexpectedly—about new possibilities and ideas to explore about a problem, but without the certainty of which is right.
Examples
- While showering, you suddenly see a connection between a historical migration pattern and your thesis argument. Intriguing, but you have no sense of how you got there.
- A designer glances at a cracked sidewalk and instantly gets a hunch that the branching motif could work for a poster concept.
- Halfway through a conversation about music theory, you get the nagging feeling the same concept might explain a bug in your code.
2. Auto-Convergent
Object-level autonomous convergent thought

What it is
Expert intuition, fast heuristic matching, recognizing the right answer without deliberation.
It's the a-ha moments when the solution reveals itself without you really trying, or when the implications of what you just learned suddenly click.
Examples
- A chess player looks at a position and immediately knows it's lost: no calculation, just pattern recognition from thousands of prior games.
- A seasoned editor reads one sentence and instinctively spots the passive construction that's draining the paragraph's energy.
- A nurse glances at a patient's posture and skin tone and knows, before looking at any chart, that something is wrong.
3. Meta-autonomous
Meta-level autonomous thought

What it is
Gut-level monitoring: surprise, dissonance, the nagging sense something's been missed (alerting), as well as felt coherence, pieces clicking together, fluency-based confidence (confirming).
Examples
- Reading a technically correct AI-generated paragraph and feeling something is off. You feel a vague unease before you can name what's wrong.
- The satisfying click when the last piece of a complex proof slots in and the whole thing suddenly feels obvious.
- Unexpected boredom while reading a source, before consciously realizing you've already extracted everything useful from it.
4. Algo-Divergent
Object-level algorithmic divergent thought
What it is
Systematic exploration, enumerating options, combinatorial search, structured analogy, running thought experiments.
It's the mechanical work of finding information, setting up boilerplate, or collecting raw data. When Sherlock Holmes is hunting for clues in the middle of a case, he is mostly doing algo-divergent work.
Examples
- Systematically searching the literature for all studies on a topic, building a spreadsheet of findings and keywords, before drawing any conclusions.
- Listing every possible cause of a software bug by category—environment, input, logic, dependencies—before testing any of them.
- Running through all combinations of available fridge ingredients before deciding what to cook, to avoid missing a better option.
5. Algo-Convergent
Object-level algorithmic convergent thought

What it is
Step-by-step derivation, calculation, following logical chains.
It's the mathematical, logical, rational work of reaching an answer. What Sherlock does once enough pieces of the puzzle have surfaced, culminating in the grand reveal of the murderer.
Examples
- Evaluating a definite integral step by step, checking each algebraic manipulation before proceeding to the next.
- Tracing a program's execution line by line to find exactly where the output diverges from the expected result.
- Eliminating crossword candidates one by one using letter constraints until only one option remains.
6. Meta-algorithmic
Meta-level algorithmic thought
What it is
Systematic process-checking: tracking coverage, noticing repetition, checking breadth, but also auditing whether the problem decomposition itself is right. Verifying steps against constraints and checking consistency.
Examples
- Realizing mid-literature-review that you've only searched English sources, and the most relevant work might be in another language.
- Checking your task list and noticing you've been ticking off easy items while consistently deferring the one that actually matters.
- Pausing to ask whether the categories organizing your research are exhaustive, or whether you've silently omitted an entire dimension.
7. Reflective-Divergent
Object-level reflective divergent thought

What it is
Questioning your framing, generating alternative perspectives, asking "what if I'm looking at this from the wrong angle?"
When you take a step back and reassess the situation, you're doing reflective-divergent work.
Examples
- Midway through analyzing a business failure, asking: "Am I assuming this was a management problem? What if it was a market-timing problem?"
- Noticing you've never made your definition of "success" explicit, and that might have misled other people and caused confusion.
- Recognizing that the problem you've been solving is actually a symptom, and trying to name the upstream cause instead.
8. Reflective-Convergent
Object-level reflective convergent thought

What it is
Applying values, weighing incommensurables, deciding: committing under uncertainty and accepting trade-offs.
This is when you act on what you've thought so far. It's no longer just about the problem; it's about your own stance, relation, and effect on it (real or potential).
Examples
- After weeks of weighing job offers, accepting one: it's not perfect, but you feel like it's high time to commit to something.
- Cutting a beloved essay section that undermines the core argument, even though it took a week to write.
- Deciding to report a colleague's misconduct despite the social cost, because your values leave no option you could respect.
9. Meta-reflective
Meta-level reflective thought

What it is
Epistemic self-examination: generating hypotheses about your own biases and limitations ("Am I anchored? What would someone different see?") and judging whether your reasoning process has met your own standards of intellectual honesty.
Here is the difference from "mere" reflective thought: in the (object-level) reflective-divergent category, I gave the example of asking "what if I'm looking at this from the wrong angle?"; the meta-reflective equivalent is asking "what factors lead me to look at things from the wrong angle?"
Examples
- Asking yourself: "I keep reaching the same conclusion on this topic—is that because I'm right, or because I built my whole framework to produce it?"
- Noticing that using an AI to research this subject always leaves you feeling reassured, and wondering if that's a sign of confirmation bias19.
- After a decision: "My argument felt airtight, but I only tested it with people who already agreed with me. What would a real stress-test look like?"
Thoughts, Mental Fatigue, and Time
Some categories of thought can be safely delegated to an AI and, unfortunately, these aren't always the categories that you would like to delegate. So what would people gladly outsource, if possible? The most consistent answers you'll get are: the mentally tiring tasks, which are perceived as "difficult", and the time-consuming tasks.
In this section I'll offer very rough estimates of these two salient implications of thought. Needless to say, these things can't be generalized without gross oversimplification, because thought can be literally about anything imaginable. The estimates I give are general trends based on the few scientific experiments about these things and on my own experience in various fields and roles.
The Panting Mind
The human body is excellent at optimizing its energy consumption, and the brain is no exception. As you're probably all too aware, the brain naturally falls into the least-tiring approach that it considers enough20 to solve a problem—even if it's not the best approach 21. You can usually tell which thought processes would be tiring because you intuitively feel they are hard.
What are the most tiring categories of thought along the three axes of AAT? Knowing the typical mental cost (a.k.a. cognitive load) of each category will tell you how the average person will tend to think, and what they'll try to offload to AI.
A major "cost center" of the brain, acting as a biological bottleneck for intense thought, is the lateral prefrontal cortex (LPFC), on the front-facing surface of the brain. This area handles working memory, reasoning, planning, and conscious imagination—all ingredients for the most advanced forms of rational thought. Several studies 2223 have shown that the metabolism of the LPFC (and related regions, like the anterior cingulate cortex and the parietal cortex) gradually changes when it is activated for longer periods. Glutamate and other toxic substances accumulate, making activations in those areas increasingly costly for the brain. This may explain why the brain seems to fall back to lower-effort options when fatigued 24.
(By the way, this is different from the now-infamous "ego depletion" effect by Baumeister et al., which has now been largely debunked25.)
Other regions of the brain, like the default mode network (DMN), don't experience the fatiguing effect seen in the LPFC. Although people (understandably, given the name) tend to think of the DMN as "the thing the brain does when it's idle", this brain-spanning web of neurons also plays a role in low-effort thinking 26, including memory retrieval, future planning, and hypothesis generation 27. On the Phase Axis of the AAT framework, these are particularly important during the divergent thinking phases, which correspond with creative output.
Unfortunately, things are not as simple as they sound, because divergent thinking is a collaboration between various networks, and the brain has to switch back and forth between the DMN, the PFC, and other regions 28, which likely adds to the cognitive overhead 29. The details depend on the specific task, but as a rule of thumb the divergent phase starts with a heavier focus on memory retrieval, which is not very tiring, but draws on the executive networks (like the PFC) more and more as the brain runs out of low-hanging fruit from memory—it has to get busy actively hunting for the less-obvious ideas 30. This means that, in a single session of divergent thought—especially in unfamiliar algorithmic search tasks—the mental fatigue profile can rise from moderate to high.
On the Mode Axis, unfamiliar algorithmic work is generally rather tiring for the PFC. It requires you to hold multiple interdependent elements in your working memory at the same time 3132. For repetitive, pattern-like algorithmic tasks, however, you usually learn to break them down into small, near-effortless, standardized, but tedious steps, turning this work into something almost autonomous. For example, with the right technique (probably involving pen and paper), making a list of all possible combinations of three letters becomes a mechanical, even easy task—but still time-consuming. The same happens with algebra, once you've internalized its rules: it lets you simplify any algebraic expression with the same ease, regardless of how huge or complex it is.
This point bears repeating, as it will come up again: whether a logical chain of thought is pattern-following or irregular makes all the difference for how tiring it is for a human, how fast they can execute it, and how much reflection is needed to guide it.
Using the reflective mind also tends to be rather tiring, especially in the convergent phase. Overriding your first instincts, inhibiting bad habits, marshalling the necessary information and, crucially, deciding what to do next are some of the added demands on your prefrontal cortex.
This gets even tougher with the meta-level thought processes on the Level Axis. fMRI studies tell us that "thinking about thinking" is an extra layer of thought on top of the object-level activations, associated with its own specific areas (the rostrolateral PFC) 33, and that it adds its own contribution to the metabolic shift and fatiguing effect of thought 34. If you've ever tried genuine rational self-examination, this much shouldn't surprise you.
People tend to skimp most on the meta-reflective ⓘ work, especially on routine tasks or under time pressure 35. In practice, I think most people avoid spending any significant time doing meta-reflective work, partly because of its high cognitive load.
The problem is counterintuitive, because the main job of metacognition is optimizing object-level thought. You know what I'm talking about if you've ever caught yourself thinking "I'm getting fixated on this again, but I know it's never worth my time" or "I already know how this discussion ends, let me change approach." Used well, the meta level can actually decrease the amount of effort (and time) needed to solve the problem, perhaps by correcting a misleading bias of yours, or prompting a reevaluation of your goals. But it is itself a tiring task 12.
If things weren't hard enough, distractions exist! A recent experiment showed 36 that it takes more effort to shield working memory from external distractions than it takes to update the contents of your working memory. In other words, staying focused on your train of thought has its own intrinsic price. For long-running thoughts, like algorithmic tasks, this cost can add up.
Guesstimating Time Spent
The second factor that matters when delegating (or not delegating) thought is the time you spend in each cognitive category. Some problems need to be tackled regardless of how mentally tiring they are, and how long each step takes can matter a lot. If a computer can do it at 10x or 100x the speed, you'll probably want to have the computer do it for you.
Unfortunately, on this front we have to rely on breadcrumbs of research, because empirical data about the time costs of each cognitive category is scarce. The ninefold subdivision of this framework is my invention, so it's natural that no research has explicitly measured process durations in each of those nine cells. We'll have to work with what we have and fill in the gaps with educated guesses, one AAT axis at a time.
First, the Tripartite Mind axis. We do know that the autonomous mind is fast (it's Kahneman's System 1, i.e. the "fast" in Thinking, Fast and Slow), and that the other kinds are slow. But, as far as I can tell, there hasn't been a systematic study of the timing differences between Stanovich's algorithmic and reflective minds. They may be too intertwined to measure meaningfully, or it may just be too early.
What we can say is that algorithmic work can be indefinitely long, while reflective work tends to be more bounded: any specific calculation approach can have any number of steps, but there are usually only a handful of alternative approaches you can consider. As an extreme example, consider the problem "find the smallest prime number that has exactly 10 digits". Claude Opus proposes five strategies to solve it, but tells me that the most promising (i.e. fastest) of these strategies would take about 400 mathematical operations, and the least promising about 75,000! The mechanical work, if you were to actually carry it out, would involve orders of magnitude more steps than the reflective work that guides it.
In other words, both algorithmic and reflective thoughts are slow, but algorithmic work can (though it doesn't always) take much, much longer than the reflective work that guides it.
The picture isn't much clearer for the object vs. meta axis: metacognition takes time 37, but we don't know how much. The deeper problem is that different people seem to operate at the meta level far more than others, and some seem to avoid it entirely (this is my own observation; frequency of metacognitive thoughts is a recognized research gap 38).
So the question of how long metacognition actually takes is probably moot. Instead, let's consider how long it should take ideally: too little and you won't (even) learn from your deepest mistakes, too much and you get paralyzed in self-analysis. The counterintuitive part is that, done long enough, metacognition can significantly reduce the time you need to think at the object level: you avoid many pitfalls and false starts, stop wasting time on irrelevant thoughts, and generally keep your thought process healthy and efficient.
For this reason, I think a good target for metacognition in complex problem-solving is somewhere around 20% to 30% of total thinking time (with massive uncertainty bars!). This is probably more than most people actually spend at the meta level, or consider appropriate. Maybe I'm overestimating it, but lowering the estimate only makes my discussion below about augmented cognition stronger, so I'll be conservative here.
Now for the third axis: what are typical divergent and convergent thinking times? There seems to be even less research comparing these two phases than the other two subdivisions. Psychologists do seem to agree that they are not two sequential steps but a cycle, with thought going back and forth between diverging and converging at irregular intervals. But how long do (or should) we dwell in those intervals? No one seems to have even asked the question. In a case like this, I'll just shrug and say that, to the best of our (poor) knowledge, the two have a 50-50 split of time. Precise estimates are not important here.
All in One Table
Based on all the above, we get a map like this:
Scroll to see the rest →
| Category | Cognitive Load | Time Cost |
|---|---|---|
| 1. Auto-divergent ⓘ | Low. Runs on DMN; minimal prefrontal cost. | Near-instantaneous, moments of insight, often coming to you while you're doing something else. |
| 2. Auto-convergent ⓘ | Low and automatic; barely registers as effort. | Very short, moments of insight. |
| 3. Meta-autonomous ⓘ | Low, signal-like; largely automatic and metabolically cheap. | Brief moments of insight or gut feelings existing in parallel with conscious thought. |
| 4. Algo-divergent ⓘ | Can be low for familiar, pattern-like tasks. For novel and un-pattern-like tasks, this usually starts moderate (you need to keep several factors in your working memory) but can escalate as the low-hanging fruit runs out and DMN-ECN switching intensifies. | Potentially extremely long, regardless of how tiring each step is. For many knowledge workers it dominates the workday. |
| 5. Algo-convergent ⓘ | Potentially low for familiar, pattern-like tasks (e.g. algebra). High for novel domains: it's pure working memory + executive control; the recipe for prefrontal fatigue. | Potentially extremely long. The more you diverged earlier, the more work you have to do to narrow down the answer. |
| 6. Meta-algorithmic ⓘ | Moderate/heavy. Executive function monitoring executive function, i.e. a second prefrontal layer on top of object-level work. Depends on the task: simple monitoring is much cheaper than auditing. | Potentially long. Difficult to separate from object-level algorithmic work, as it has to happen at the same time. |
| 7. Reflective-divergent ⓘ | High. Requires executive override. | Moderate in general. |
| 8. Reflective-convergent ⓘ | Very high. Inhibition, value comparison, and commitment, all at the same time. Peak prefrontal demand. | Moderate. Includes planning time, debugging, etc. |
| 9. Meta-reflective ⓘ | Very heavy, perhaps the most expensive metacognitive operation: requires sustained self-directed prefrontal control with no external scaffolding. | Ideally quite long, as it is the most powerful category of thought in the long term. In practice, usually short. |
Part 2: Augment
Careful What You Hand Over
You Might Also Like...
At this point you might be wondering whether defining all those categories and making crude estimates of mental fatigue and time costs was really worth the trouble. I think it was, because—imprecisions and all—now we can use it to structure our answer to the big questions of if, when, and how to delegate thought to a (general purpose) LLM. We get nine answers instead of one, and even if each may not be very precise, I think the ensemble lends some much-needed nuance to the discussion on augmented thought.
Here is a brief review of how to think about delegation in each of the nine thinking categories, one by one. After that, we'll step back and look at the full picture.
The AI's Territory: Things You Can Happily Delegate
General-purpose language models like GPT, Claude, and Gemini come with vast computational power but zero accountability, lived intuition, and consistent intellectual honesty, so we can start with the obvious insight: algorithmic work is the paradise of augmented thought.
I'm talking about the systematic, quantitative, or combinatorial heavy lifting. These are the areas that usually take up the most time in "knowledge work", and are often (though not always) cognitively tiring. An LLM can do them at a mind-numbing speed while you stare out the window sipping your tea. It's a match made in paradise, and the part that gets closest to being an actual magic wand.
Algo-Divergent: Delegate 🤖
You can usually delegate most Algo-Divergent ⓘ work to an LLM, which consists mainly in the systematic exploration of options, sources, and ideas. Especially in the early low-hanging-fruit phases, simply letting the model produce options from its training data is valuable and cheap, with little downside—filtering out errors and hallucinations is the job of other categories.
This is brainstorming territory, so there are (almost) no wrong answers. Still, letting the AI run wild almost guarantees that it will miss certain possibilities and directions. Models tend to bias their searches toward whatever their initial attention lands on.
This is where the human comes in: you need to set precise goals and boundaries, steer the model when it gets stuck or clearly biased, and ask it to ground its search in reliable external sources or even use code for more systematic surveys (all reflective and/or meta inputs).
Do this well, and the LLM can enhance your creativity 39. The point is not to get high-quality options on average (you won't) but to unearth the occasional big leap in insight.
Algo-Convergent: Delegate 🤖
You can fruitfully delegate this category to an LLM too, but with more care. Artificial neural networks like today's transformers are probabilistic algorithms: they tend to give the most accurate next answer, but offer no guarantees. This makes them unreliable at logic and math in general, and you can't trust them to one-shot the right answer 4041.
AI models are cajoled into parroting logical thought like a trained monkey dances to a tune. Trained or not, you don't want a monkey piloting your aircraft.
Still, the benefits of what it can get right are so enormous that people have put a lot of work into mitigating this unreliability. This is the realm of most software engineering use cases (at its core, coding is algorithmic convergence). Engineers have devised approaches like iterative refinement42, adaptations of test-driven development, multi-model reviews, and many more to improve the trustworthiness of AI algo-convergent work. We're still far from 100% reliability, but it's an exciting and fast-moving field.
The role of the human, here—and not only in software—is to vet the process and the results critically, do reality and plausibility checks, and interrogate the LLM whenever it seems to have made leaps in reasoning. In other words, you trade object-level grunt work for meta-level control work. More on this below.
A key tool you should use whenever possible to drastically improve the results is asking the LLM to solve the problem by writing a program, rather than relying on worded reasoning alone. Modern language models are very good at putting together quick scripts, and usually come with the infrastructure to run them on the spot. You can think of code as the routinization of an LLM's algorithm, similar to how internalizing a routine algorithmic task (e.g. mastering algebra) makes your own algorithmic work less mentally tiring and more reliable. The difference is that code is mind-numbingly faster.
The Middle Ground: Tight AI-Human Collaboration
Being "algorithmic" isn't all that an LLM can do. The large state-of-the-art models of today have immense latent spaces—maps of knowledge about almost any topic known to humankind. AI knows about everything.
The problem is that these knowledge spaces are unstructured (compared to any reliable database) and too vast to fully wrap one's head around. This is why some AAT thinking categories need to be joint efforts, where the AI provides the data and patterns but the human is the one who actively navigates.
Auto-Divergent: Joint Work 🧑🦰🤖
This is the kind of divergence work that comes automatically. Unlike systematic explorations and algorithmic brainstorming, auto-divergent ⓘ thinking just happens, unplanned. For a human, this means hunches and leaps of insight. For an LLM, it's the surprising connections it pulls out of its training data 43. If you ask it for ideas to name your baby, it can produce any number of ideas seemingly from thin air. Auto-Divergent is where most of creativity happens.
This is a delicate task to delegate to an AI. On the one hand, it can genuinely expand the range of ideas you consider; on the other, it can skew you toward the same pool of ideas as every other AI-assisted thinker 4445. On top of that, reading the novel associations offered by an LLM can reduce the number of original ideas your own brain produces and make you feel less invested in the work 46.
Often this doesn't matter: you just need a good enough idea, and being maximally original is not a priority. In these cases, giving the LLM free auto-divergent reins is probably fine. But when originality matters, you can get the best of both worlds by first brainstorming without the AI, then asking it for its ideas (without biasing it with yours). The resulting pool will be a mix of your own creativity and that of the model's training set.
Reflective-Divergent: Joint Work 🧑🦰🤖
It's very common to struggle with a problem because you're thinking about it the wrong way. You make the wrong assumptions, draw the wrong boundaries, and things don't make sense to you. Or you might be able to reason your way through the question but find it very confusing and tiring. You need to reframe, to change your point of view and angle of attack. That's easier said than done, because framings are very sticky—the longer you've held one, the more it will seem like the way reality works.
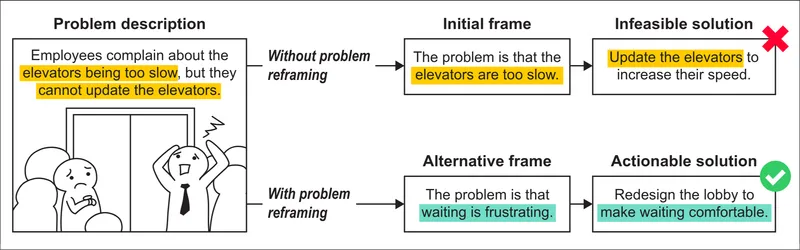
This is where an LLM can really get you out of your thinking rut. It will offer as many new framings as you want and, although most will be clumsy or moot, some might be just what you need to see the limitations of your original way of thinking. Under the right conditions, asking an AI for reflective-divergent assistance can speed up the work of reframing.
I worded that last sentence carefully. There are two strong limitations in using LLMs here. First, you apparently need to be already quite competent in the problem's domain to benefit from the speed-up in reflective-divergent ⓘ thought 47. If you're a beginner and don't have the problem-solving muscles for that kind of problem, an AI may not help you reframe much at all. Second, even if you're a domain expert, whatever benefit there is to augmenting this thinking category seems to be mainly in speed—the number of reframes you can explore in a given time—and not in their quality 47. (I'll return to the role of expertise in the Expertise Matters Doubly section below.)
In other words, an LLM might—maybe—make your reflective-divergent thinking somewhat smoother, but only if you're both already good at it and you put in your own effort.
Meta-Algorithmic: Joint Work 🧑🦰🤖
Meta-Algorithmic ⓘ thinking is about structuring the process in a logical and appropriate way. The good news is that part of this work can be standardized and shared. There is, in fact, a whole cottage industry of pre-packaged "mental models" and "n steps to do x" recipes—it's a big portion of the self-help industry and business manuals: Five Whys, OODA loops, six thinking hats, project management waterfalls, product lifecycles, lean processes, six sigma, code boilerplate, and many more.
The even-better news is that your LLM knows all of them. Throw a common problem at it and it will readily produce a neat, well-organized thinking framework to solve it. This is excellent and there is no reason not to delegate this otherwise tedious work to the machine.
Except... your deep involvement is still necessary. The fact that an AI can produce an advanced framework made by seven PhDs and battle-tested by three generations of Druckers doesn't mean it's the right framework for your specific case.
Only you know the full details of the problem you're trying to solve, your short- and long-term goals, and the risks and opportunities involved. No matter how much context you give the LLM, a fundamental decision like which thinking process to use can only be vetted and chosen appropriately by your carbon-based brain.
So yes, let the AI handle the skeleton of the process, but audit its decisions critically at every step.
The Human's Territory: DIY
Things may change in the future, but there are some forms of thought where current LLMs do more harm than good 48. These are the mental tasks that keep the delegated categories of the previous two sections on track. They rely on lived experience, accountability, and full metacognition, and they should remain fully human-generated. Delegating them can lead to cognitive atrophy 9101149, and will make it almost impossible to reach consistently good, reliable results.
People who delegate these categories to LLMs are, in my assessment, the main cause of the lack of measurable performance boosts from AI: they have the machine generate lots of nice-sounding outputs, but those outputs are answers to the wrong questions, or contain bugs that pass unnoticed until it's too late.
Auto-Convergent: Do It Yourself 🧑🦰
This is the instinct that lets you recognize the "right" answer on the spot, without reasoning steps. It's shaky in humans and utterly unreliable in LLMs. Since it takes very little time and effort regardless, there is no reason to delegate it.
Reflective-Convergent: Do It Yourself 🧑🦰
This cognitive category is one of the most important and consequential, because it's where you decide what to do in the next step. To decide well you need to apply your values, weigh fuzzy trade-offs, and commit under uncertainty. An LLM can lay out the options and costs (an algo- or reflective-divergent job), but only you can make the call. Reflective-Convergent thinking is where accountability and consequences reside.
Trying to think with an LLM in this cell of the AAT matrix is a risky business.
One problem is that tasks that seem algorithmic on the surface sometimes hide reflective-convergent ⓘ decision points inside them, where uncertainty or contrasting options exist. The model might simply choose the wrong path at some point along its long chain of algorithmic steps and silently proceed to crunch the wrong numbers for a while without you noticing. It's very important to prune as many of these branching points as possible before the LLM begins its algorithmic work, and to ask it to stop and request clarification whenever it's unsure about something.
Then you have to deal with the even more insidious hazard of being hypnotized by the AI's own narrative 50. An LLM will always try to quietly colonize the reflective-convergent mode—it will offer fluent explanations and rationalizations for why the answer it gave you is absolutely the right one and, if you're like most people, it will probably persuade you. Research has shown that people not only tend to go along with the AI's stories even when they're wrong, but they usually feel like they made the call 5019!
If you use your LLM-augmented output for anything serious, "but... AI wrote it!" won't be accepted as an excuse when that output turns out to be bad.51 The only sane choice is to never delegate value judgements and key design decisions to AI, and to actively distrust its proposals—all the more so when they seem convenient to you.
It's not a coincidence that most of the impressive advances in LLM use for coding are ways to prevent the models from doing reflective-convergent work. 525354 The software world nowadays has an endless stream of new techniques to effectively structure the AI's process before starting, to provide all the context that might become necessary along the way, and to ensure the human gets to make all the important decisions. One of my projects is to free these methods of their engineering baggage and make them accessible to non-technical people, too.
Meta-Autonomous: Do It Yourself 🧑🦰
Gut-level monitoring is the intuition of whether something is missing or off (cognitive dissonance) or whether everything checks out and clicks (fluency). The LLM can't do that for you—it will always craft things in a way that appears to click. Meta-autonomous thinking is your first line of defense against those treacherously smooth stories the AI tells you, and you should pay attention to these instincts. Fortunately, this is not a mentally tiring operation, so you can keep it "always on" in the background as you work through the other thinking categories.
But not all gut feelings are equally reliable. If you get an alert signal ("something feels wrong here"), you can bet it's right. Pursue that lead like a hound, dig as deep as you need to, until you clear it completely. When a confirming signal fires in your mind ("this makes sense"), on the other hand, you might very well be wrong, tricked by the artificial fluency of the transformer's output. Treat such confirming gut reactions as noise, and perform the algorithmic and reflective due diligence to ensure the output is really correct.
Meta-Reflective: Do It Yourself 🧑🦰
Lastly, metacognitive reflection is the most meta of thought processes, and the single most important human contribution to the quality of thought—augmented or not.
Meta-reflective ⓘ thinking is, in general, the realm of epistemic self-examination; when working with an LLM, it's how you keep the model on track and near peak efficacy. Understanding and applying this Anatomy of Augmented Thought framework is itself a meta-reflective ⓘ function.
You should never skimp on this, even though it's one of the more mentally demanding jobs 5556. In fact, I don't think it's possible to produce anything more than highly generic and mediocre results without deep meta-reflective effort. Keep this cell of the AAT matrix fully yours: steer it, manage its context, craft careful prompts, and use "doubt engineering" techniques (these are the topic of a future post).
Fortunately, LLMs are steadily improving at meta-reflective support thanks to techniques like structured chains of thought, prompted self-critique42, and multi-model reviews. These improvements can take some of the cognitive load off your brain, but not much: LLM mistakes are also becoming subtler and harder to spot, so the harder part of this work remains squarely a human task.
In Summary: The Delegation Grid
, LLM (algo-divergent, algo-convergent), or Joint (auto-divergent, meta-algorithmic, reflective-divergent), with a brief description of the task")
Augmented Thinking: Faster and Slower
Using an LLM for work is alluring, first and foremost, for its promise of incredible time savings. It feels like magic! Things that might have taken hours can now be produced in a minute. People who value their time can't resist the temptation, and they generally report feeling much faster and more productive with AI. But the empirical data tells a different story: companies are still not seeing the wondrous explosion of productivity promised by the advocates 57 58.
We have a paradox. If everyone says they're producing more, why doesn't macro-level productivity soar? It could be that individuals are absorbing the time savings to finish early and take longer breaks from work 59, but that's a rather extreme hypothesis at the aggregate level, and there are studies saying that people are actually busier than ever because of LLMs 60.
I find somewhat more convincing the idea (partly backed by research 61) that AI-assisted people end up trying to do more in the same amount of time—including nice-to-have things and gold-plating that add complexity and don't contribute much value in the grand scheme of things. This increase in number of tasks leads to more multi-tasking, which is slow, error-prone, and mentally tiring (more on this later). I know this firsthand: I've gotten into the habit of working on three or four completely unrelated projects at the same time, all the time: while an AI agent is working on one of my prompts I switch to the next one awaiting my input, review its work, prompt it again, and move on. It feels productive, but I wonder how good an idea it really is in the long term.
But at least part of the explanation lies in how people use LLMs, and on what tasks. That, I think, makes an enormous difference in how they can affect productivity. We need to break free of the monolithic "is AI useful or not" framing and look into which kinds of tasks can benefit more or less from the technology, and how to get the most out of it while doing them. This is where the AAT framework can help.
Mapping Time: The Anti-Magic Effect
What time savings can an LLM offer you, assuming you follow my Delegation Matrix to the letter? Something along these lines.
First, augmented autonomous thinking categories take roughly the same amount of time: they are fast without AI, and they stay fast with its help. Not much to gain directly here. Reflective categories, according to the Delegation Matrix, remain human tasks, so the time savings in that area don't change much—if anything, you have to reflect more while working with an AI, because you need to monitor and control its approach in addition to your own. The same goes for metacognition, which is largely the human's territory and becomes especially important—non-negotiable, even—when working with the flakiness of language models.
Divergent thinking phases tend to be low-risk while surfacing the occasional gem of insight, so an LLM's results can add value even when they don't save you much time directly (as in autonomous categories). This added value, for example in the form of better framings or additional points of view, can lead to indirect time savings later on. Conversely, convergent (alliteration not intended) phases executed by LLMs are risky and potentially deceptive, often leading to indirect time costs when you later find the mistakes and have to go back and fix things.
Algorithmic tasks are the clear winners in terms of time savings. You can tell because coding remains by far the biggest AI spending category, and other major ones like IT operations, document processing, and customer support automation are mostly algorithmic in nature 6263. These are the systematic, tedious, sometimes mind-numbing tasks that would take you a lot of time but that an AI can work through tirelessly and quickly. It might even be able to write code that does it in milliseconds.
In summary, all things considered, my rough assessment of the time effects of each AAT category is as follows:

Big savings in algorithmic (divergent more than convergent) work, more modest and indirect savings for auto-divergent and meta-algorithmic, and slowdowns in all other categories.
The strangest result, though, is in the meta-reflective ⓘ layer. As the delegation grid showed, this is a human task, yet you should expect to spend significantly more time on it when working with an LLM, not less. AI introduces a host of failure modes that typically don't exist in solo work, like confabulation and plausible-sounding flawed narratives, and these require you to constantly ask: "am I trusting this output because I've verified it, or just because it made a long and coherent argument?" 50
Call this the Anti-Magic Effect: using the "magic wand" can be harder work than not using it! Without heavy meta-reflective effort, it doesn't matter how much time you save on the algorithmic work: the outputs will be useless at best, harmful at worst, in the wrong format, and their flaws hard to fix 1241.
In practice, this means we all need to invest in honing our metacognitive and reflective skills. The fact that we naturally tend to shy away from precisely these kinds of tiring mental chores 64 (see When Fatigue Steers in Your Stead below) makes this habit all the more urgent.
To Augment or Not to Augment
Problem-solving in the real world is always some mix of all nine cognitive categories. If not all augmented thinking is equally time-saving, it follows that not all projects will benefit equally from an LLM's participation. Let's take two somewhat extreme examples.
Some office jobs are almost entirely algorithmic in nature. The work isn't necessarily difficult or confusing in itself, just long and mechanical. This includes tasks like inventories, formatting long documents, cross-checking sources, and writing variant after variant of the same kind of code. In such cases, the before-after picture of how you spend your time might look like this:

In other words, although the Anti-Magic Effect means you have to spend more time on reflection than you would otherwise, the LLM's time savings in the algorithmic part offset that by a wide margin, and you get a huge boost in productivity. This is the ideal use case for AI, and honestly a no-brainer: go for it!
Other tasks look more like this:

Here, from the outset, the algorithmic part accounts for a much smaller fraction of the task's necessary work, and the reflective part is already predominant without AI. In cases like this, the algorithmic boost may not be enough to outweigh the added reflection time. There are many tasks at this end of the spectrum: opinionated creative work, tackling very novel and exotic problems, working through emotions are some that come to mind.
The point is that some jobs can actually take longer with an LLM than without. This doesn't mean you should never delegate tasks like that to a machine—the inspiration and hints it gives you might still be valuable, and help you increase the quality of your work—but you should at least be aware of its negative effects on productivity.
What kinds of tasks are most reflection-demanding? As a rule of thumb, you need to put the most effort into carefully monitoring and steering the LLM during convergent phases, because this is where every wrong step has the biggest consequences. And a convergent thought process needs more attention the less pattern-like it is. Some algo-convergent ⓘ tasks, in particular, can be long sequences of easy, standardized steps, which an LLM can complete accurately by referring to analogous patterns in its training data. The risks spring up mostly when the process is new, randomness-driven, or very specialized: precisely the mental tasks we found to be most tiring for humans.
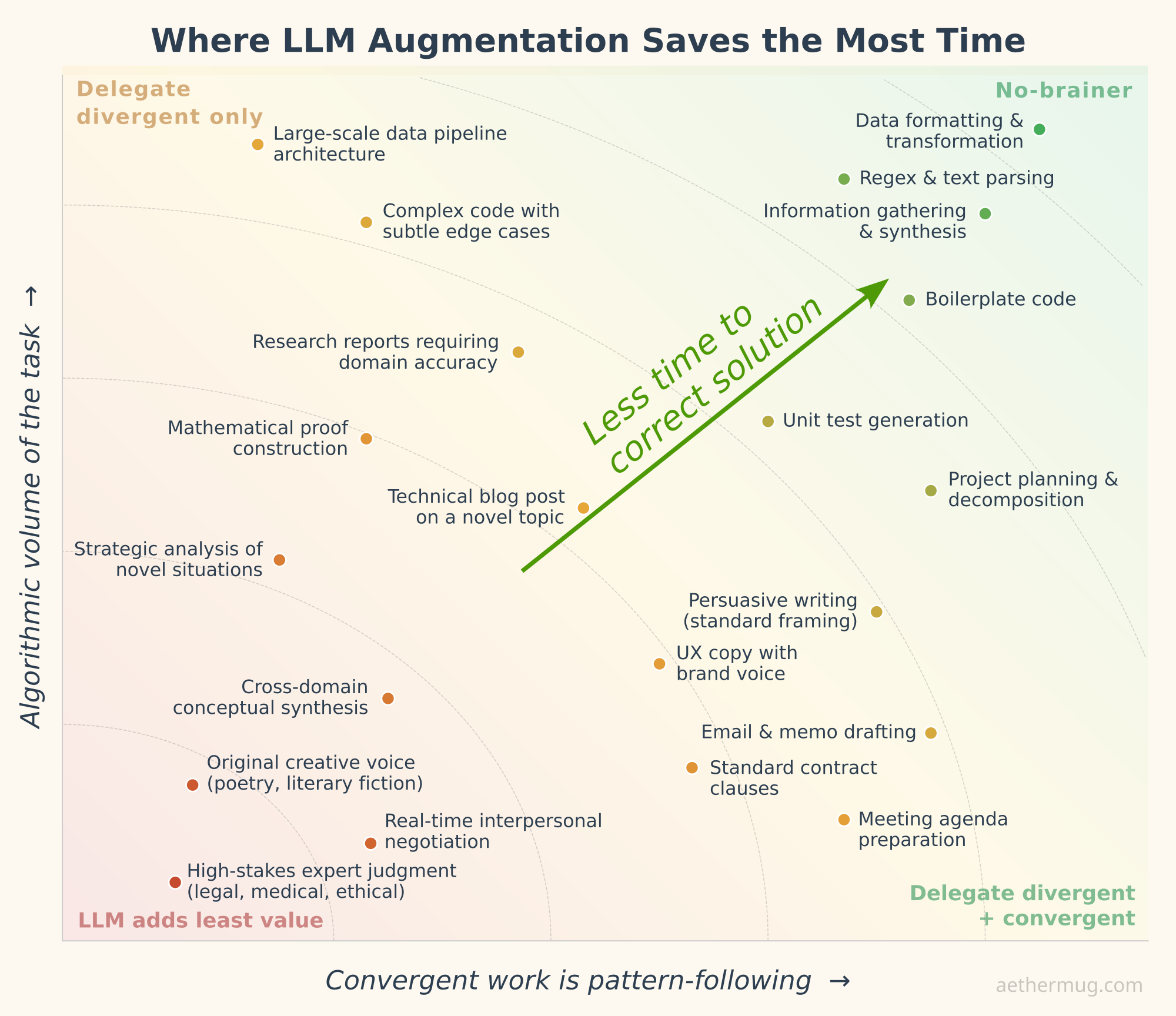
What this framing gives you is a view on the landscape of augmented productivity:
- Tasks high in algorithmic volume and based on pattern-like convergent work are LLM heaven: incredibly fast and quite accurate.
- In processes with many algorithmic steps but requiring custom and non-standard reasoning you might be more productive delegating the divergent part only, keeping the careful convergent work for yourself.
- When there isn't much algorithm involved but the convergence follows standard patterns, you can safely delegate the work to a model—just don't expect extreme time savings.
- And when the work is both non-algorithmic and highly custom, you need to seriously consider doing it all yourself to save time.
When Fatigue Steers in Your Stead
The Anti-Magic Effect means that properly augmented thought is more cognitively demanding than solo thought, and many users skimp on the meta and reflective work precisely to avoid that strain. My hope is that simply being aware that using an LLM is supposed to be hard can be enough to spur more nuanced approaches 65. The real danger, however, is that this extra strain is largely invisible.

Mental fatigue is a metabolic byproduct of using the lateral prefrontal cortex 22. The more intense, deliberate thinking you do, the more toxic substances like glutamate accumulate in your LPFC, and the less control you have over your thought processes and decision-making 24. Crucially, the same experiment that measured these objective effects also asked participants to rate their subjective perception of their cognitive abilities, and found that people were not aware of their own degradation. When your LPFC is flooded with glutamate after hours of careful prompting, you'll be more likely to accept the first reasonable-looking output the LLM throws at you, to skip the necessary "step back and critique" work, and to be generally more careless with your procedural decisions. This may be how you get experienced software developers who think they're 20% faster with AI while actually being 20% less productive 5775, and how people end up burning out more and feeling less engaged with their work 61666768 when using AI.
What to do about this problem? I don't have a very good answer yet. At the very least, being aware of this inevitable cognitive degradation during long AI sessions might help you plan your workday more carefully. In my own experience, learning to detect your own prefrontal fatigue is not entirely impossible. It took me years of daily, intensive thinking sessions and a lot of scheduling trial-and-error, but I'm now usually quite aware of when my brain has become too dumb for proper reasoning (typically after about 3-4 hours of reflective/meta thought). I'm not sure I'm able to fully compensate for all the negative effects yet, but I did see big productivity gains when I started using that knowledge.
Expertise Matters Doubly
So the optimal application of LLMs for difficult thought depends on the category of thinking you delegate, the time savings depend on the type of task, and the pitfalls are amplified by your brain's fatigue. That's a good refinement of the default black-or-white view so common online. But there's one last space we need to explore before this framework can be of use to most people: are the benefits the same for novices and experts?
Science offers some hints of an answer in this case. The short version is: of course the benefits are not the same. A longer one: not the same, and it depends in interesting ways on what you mean by "expert". In very rough terms, you could be an expert in the problem's domain, an expert in using LLMs for problem-solving, both at the same time, or neither. These are four distinct scenarios.
What does it mean to be a "domain expert" in this framework? Stanovich's tripartite mind is helpful again: when you're an expert at something, you have learned to "chunk" domain information into a few meaningful patterns 69 that you have internalized and automatized 70, i.e. you can unconsciously simplify the problem space to the minimum necessary. Your autonomous mind is your most powerful asset—essentially a sophisticated set of alarm bells to spot every awkward detail and mistake. This, in turn, supports your algorithmic thinking, because you need to hold in your working memory only those few tried-and-true learned patterns, rather than all potentially meaningful information.
A demonstration of this was given by a famous experiment by Chase & Simon (1973), in which they showed that chess masters are vastly better than novices at remembering chessboard states from actual games, but equally bad at remembering randomly-generated board states. This proved that expert chess players must be doing powerful simplification work without even thinking about it, picking up and retaining the meaningful bits of information while ignoring the unimportant details 71. This is the expert autonomous mind at work.
But specialists fare less well with the reflective mind and metacognition, because they become overconfident in their own abilities 727374, their thinking becomes entrenched 7576, and (like novices) they remain susceptible to bias from external inputs.77
As for the definition of "LLM expert", I define it as someone who
- excels at reflection and meta-level considerations,
- knows when to delegate thought to AI and when not to,
- knows which tasks are going to benefit the most from augmentation, and
- can account for their own cognitive fatigue to some extent.
This skillset is almost exactly complementary to that of the domain expert. In fact, it is largely domain agnostic.
Here is what everything we've seen up to now suggests for various types of users.
Domain Novice × LLM Novice: Tentative and Shallow
Someone who is a beginner in both LLM use and the complex problem they're tackling isn't going to be very effective with AI, because they'll be slow (lots of uncertainty, trial and error) and mostly wrong (all the pitfalls we've already covered). They don't have the autonomous monitoring skills to spot errors, so the only way they can hope to catch AI mistakes is by slowly working through the results themselves, defeating the point to some extent.
Add a sprinkling of Dunning Kruger to the mix (but not too much), and you can see how fraught an endeavor this is.
Still, AI can speed up at least the easy and standardized parts, so it's not always a bad idea for this group. The double-novice should treat the LLM as a tutor rather than an engine, using it to learn and explore more than to produce polished outputs.
Domain Expert × LLM Novice: Powerful but Inefficient
People with deep experience in a topic but unfamiliar with LLM-augmentation find themselves in an interesting predicament. They have an excellent autonomous mind that lets them catch mistakes early, but they also tend to be overconfident. If the AI gets into Yes-Man Mode (as it's wont to do), it won't point out the human's errors, simply playing along with whatever the human asserts with any conviction.
The work is also tiring for the expert, because they're not used to all the steering and prompting tricks required to get good results. They tend to under-specify or over-specify their demands, get poor results on the first try, and either start fighting the machine or give up.
I think this complex relationship with the LLM's role explains, at least in part, why experts seem to gain less from AI than domain beginners in controlled experiments (see the "Isn't AI a boon for novices?" box below). But one has to begin somewhere, and this initial struggle to get even a small productivity boost from an LLM is a necessary step toward proper thought augmentation.
Domain Novice × LLM Expert: Double or Nothing
This quadrant is a honeypot for veteran prompters. An LLM's latent space is vast beyond comprehension. No human knows so much. The fact that it is there to be extracted at any moment is a huge temptation. Why limit myself to solving problems in my own domain of expertise—asks the expert AI user—when an LLM can fill in everything I don't know?
When this succeeds, it feels enormously empowering. The world is at your cognitive fingertips—you are a super-generalist!
But this quadrant is also the riskiest. People here can't really apply their object-level reflective mind effectively, and are forced to delegate that part to the LLM. Without domain knowledge, you also have to rely on the AI to do the convergent work for you. Both of these go against the insights of the AAT framework. The usual result is highly fluent, coherent, and deeply flawed LLM outputs that the human is unable to debug.
Even assuming you do manage to get correct outputs on unfamiliar topics, you face the danger of deskilling or perpetual inexperience, never learning anything new again 78. We don't know yet how this will play out. Maybe the models and our techniques will eventually become good enough that this is the normal state for everyone; maybe it's the beginning of a global intellectual disaster.79
We'll see. Some people are pessimistic about it. For now, consider this way of using AI a high-risk, high-return gamble.
There have been several studies offering robust evidence that novices are the ones who get the biggest productivity gains from using LLMs. For instance, you'll read that "less experienced and lower-skilled workers improve both the speed and quality of their output, while the most experienced and highest-skilled workers see small gains in speed and small declines in quality," 1 and that professional writing test participants "with weaker skills benefited the most from ChatGPT." 80.
My explanations above might seem to contradict these results, but I don't think they really do. The studies above focused on standardized, relatively-easy tasks like boilerplate writing and customer support, i.e. high-algorithm and high-pattern, precisely the kind that gets the biggest productivity boosts from LLMs, and the kind that experts are already quite fast at. It makes sense that inexperienced people would get the biggest share of benefits there.
This Anatomy of Augmented Cognition framework, on the other hand, is specifically about complex/novel problem solving and long and difficult thought processes. Here the evidence tells a different story, because the moment you step outside the LLM's training scope, your autonomous alarm bells and meta-reflective work begin to make all the difference. Novices don't do well in those cases 81.
Domain Expert × LLM Expert: Full Augmentation
Needless to say, the Goldilocks zone is when someone is both experienced in the topic of study and skilled at augmented cognition. This combination allows you to delegate exactly what can be delegated and nothing more, while catching mistakes early and limiting the most tiring mental work to the categories of thought with the most leverage.
In my very anecdotal experience, almost all of those working in this quadrant today are software developers. I haven't heard of many people expertly doing highly complex, sustained, useful work with LLMs outside of coding. This doesn't mean there aren't people doing that (there must be some), but I do believe there is an enormous gap here. This is the main reason I'm writing this post: I feel we can and should democratize LLM expertise.
| LLM Novice | LLM Expert | |
|---|---|---|
| Domain Novice | 🟡 Won't get far | 🔴 High risk bet |
| Domain Expert | 🟡 Powerful but inefficient | 🟢 Full augmentation |
Conclusions
You can't conquer a land you don't know the lay of. The relevant science is still in its embryonic stages, and there is much left to research about human-AI problem-solving. Outside of the labs, we hear lots of fragmentary reports of how much AI helps, whether it hurts more than it helps, and all the risks and horror stories, but we don't hear enough about how and when and why we can use AI to greater or lesser benefit (with notable exceptions, of course: see for example Ethan Mollick, Maggie Appleton, Andy Clark).
Nor is it a theoretical topic we can leave to specialists the way we generally can with particle physics or medicine. We are all practitioners. This post is my attempt at mapping the landscape as granularly as possible, hoping it helps others orient themselves toward a nuanced relationship with this strange emergent skillset.
I found that simply having a rough map like this—shaky as it is—offers useful insights almost for free. In closing, I'll summarize my three major takeaways from this exploration.
For a recap of all pitfalls and gotchas of augmented cognition mentioned in this post, see Appendix I.
First, contrary to popular belief, serious augmented thought isn't supposed to decrease the mental strain on people's brains. In fact, if you're not mentally strained after an LLM session, you might be doing it wrong, and already bankrupt on cognitive debt. How sustainable this high-intensity work is in the long run, and how it affects the quality of your results, is something to ponder 61.
Second, it's tempting to believe that AI, if it is any good at all, is good for every part of a project and useful for everyone and for all projects equally. This fallacy will push you into monolithic delegation: you ask the machine to cover all categories of thought, especially the tiring work of carefully steering, deciding, and monitoring the models 21. As we've seen, AI can be very helpful, but only on certain processes, and only for people with certain know-how. For some projects it won't even be worth the mental overhead.
The last takeaway is that being very good at the meta-work of using an LLM is critical for any serious endeavor with it82. Contrary to popular belief, this new technology is not creating a generation of sorcerers who solve every problem simply by purchasing a subscription. When it comes to LLMs, cognition becomes the main subject of human thought. Understanding it as well as we can is non-negotiable, like mastering human anatomy is non-negotiable for any artist who wants to draw people. Metacognition is the skillset that makes the difference.
- Using an LLM well is hard work
- LLMs can only help on some parts of some projects
- You need to become an expert meta-thinker
At the very beginning I mentioned a worrisome lack of large-scale productivity gains in organizations that have invested heavily in AI. Individuals often claim (and sometimes prove) that LLMs help a lot, but companies beg to differ. The AAT framework offers an explanation for that—perhaps it's a problem of wrong expectations.
Investing millions to equip your workforce with state-of-the-art LLMs won't make a difference unless they all suddenly become meta-reflectively ⓘ skilled and willing to burn through their precious cognitive resources every day. They need to sweat their prompts, orchestrate their context, and fine-tune uncertainty at every step (techniques I'll cover in a more practical post in the near future). Adjust the expectations, redirect some of that spending to training people, and things might just turn around for companies.
Most people agree that we'll soon be using AI to do much more than we do now. For simple routine tasks, I don't think we need to worry too much, and the warnings of this post probably won't apply that strictly. But if we start using LLMs to handle all of our difficult tasks, then meta-reflective ⓘ self-examination will rise to the top spot as the single most important human contribution in everything we do, and the one role that won't be replaced by machines for a good while yet.
It's time to begin teaching metacognition in all school curricula. This is the meta-era. ●
Special thanks to F.G. and A.D. for reviewing drafts of this post.
Appendix I: Pitfall Recap
This is a quick reference of the various gotchas and pitfalls mentioned in this post. Compiled by an LLM.
Auto-Divergent ⓘ: Joint Work
- Idea homogenization. Using an LLM for creative brainstorming skews you toward the same pool of ideas as every other AI-assisted thinker, pulling you away from genuinely original angles.
- Crowding out your own creativity. Reading AI-generated associations can suppress the number of original ideas your own brain produces, and makes you feel less personally invested in the result. When originality matters, brainstorm alone first, then consult the model.
Algo-Divergent ⓘ: Delegate
- Attentional bias. LLMs bias their search toward whatever their initial framing lands on, systematically missing other directions. You must actively steer them to explore alternative spaces.
- Steering overhead. You need to set precise goals, provide boundaries, and redirect when the model gets stuck or biased — none of which is free.
Algo-Convergent ⓘ: Delegate
- Probabilistic, not guaranteed. LLMs are trained to produce plausible next tokens, not logically correct ones. They are unreliable at math and formal logic; never trust a one-shot result on a non-trivial derivation.
- Hidden decision joints. Long algorithmic chains often contain implicit branching points where the model must make a judgment call. It may silently choose wrong and keep running, compounding the error invisibly before you spot it. Prune ambiguities before handing off the task, and instruct the model to stop and ask when uncertain.
Reflective-Divergent ⓘ: Joint Work
- Domain competence required. The speed-up in reframing that an LLM can provide only kicks in if you're already quite proficient in the problem domain. Novices gain little or nothing from AI reframing assistance.
- Speed, not quality. Even for domain experts, the benefit appears to be mainly in the number of framings you can cycle through per unit time, not in the depth or quality of each reframe.
Reflective-Convergent ⓘ: Do It Yourself
- AI colonizes the decision. An LLM will always attempt to quietly fill the reflective-convergent role — offering fluent rationales for why its output is correct. People regularly go along with this even when the output is wrong.
- Illusion of agency. Research shows that people typically feel they made the final call even when the AI effectively made it for them. Accountability stays with you regardless.
- No excuse accepted. If an AI-assisted output causes harm or is simply wrong, "but the AI said so" is not a defense. Treat every AI-generated decision recommendation with active suspicion, especially when it conveniently confirms what you already hoped.
Meta-Autonomous ⓘ: Do It Yourself
- Artificial fluency masks real gaps. LLMs always craft output that sounds coherent and complete. You cannot trust a confirming gut feeling ("this makes sense") when reviewing AI-generated text — the fluency is cosmetic, not epistemic. Treat confirming signals as noise; pursue alert signals like a hound.
Meta-Algorithmic ⓘ: Joint Work
- Framework mismatch. An LLM can produce a sophisticated, well-sourced thinking framework and still be wrong for your specific situation. Only you know the full details, goals, and constraints — you must audit and choose the framework, not just accept it.
Meta-Reflective ⓘ: Do It Yourself
- Skimping here guarantees mediocre results. Without deep meta-reflective effort on your part, gains in algorithmic speed produce outputs that are useless at best, harmful at worst — in the wrong direction, with hard-to-fix problems.
- Subtler failures ahead. As LLMs improve, their mistakes become harder to spot, not easier. The burden on human meta-reflection increases over time, not decreases.
Cognitive fatigue and the Anti-Magic Effect
- Fatigue-induced shortcuts. Under cognitive fatigue, you are more likely to: accept the first plausible-looking output; skip critique and verification steps; make careless procedural decisions. All of these compound silently.
- Fatigue is invisible. Mental fatigue degrades judgment and decision quality in measurable, objective ways — but people do not notice the degradation in themselves. You can be significantly impaired and feel perfectly normal.
- Inverted effort profile. Effective augmented work spends a larger fraction of total time in high-intensity reflective and meta-reflective work than solo work would. You may be faster overall while burning through mental resources at a much higher rate.
- Multi-tasking trap. AI's speed creates the temptation to run multiple projects in parallel while agents work. Multi-tasking is slow, error-prone, and mentally costly.
- Burnout risk. Heavy AI use correlates with increased cognitive load and burnout, not relief from it.
Expertise interactions
- Domain Novice × LLM Novice. No autonomous alarm system to catch AI errors; Dunning-Kruger effect raises confidence in flawed outputs. Treat the LLM as a tutor for learning, not an engine for producing polished work.
- Domain Expert × LLM Novice. The expert's strong autonomous mind can catch errors, but overconfidence leads to under-specified or over-specified prompts. In Yes-Man Mode, the model plays along with the expert's mistaken assumptions rather than correcting them.
- Domain Novice × LLM Expert. The most dangerous quadrant: produces highly fluent, coherent, deeply flawed outputs with no mechanism to detect the flaws. Also risks deskilling — never building domain knowledge because the AI always fills the gap.
Appendix II: Caveats and Assumptions
This post has many weaknesses due to gaps in data and/or in my knowledge. All mistakes are mine. Several of the conclusions I drew here are interpretations of scientific results, and are tentative and arguable (comment below or write to me about them!). Some of the empirical results I reference are themselves still contested and not yet fully accepted by the respective academic communities. I've done my best to list all such limitations below, but I'm probably missing a few.
The following list of caveats and assumptions is largely written with the aid of AI.
- This framework is exclusively about the use of AI for complex, multi-step "knowledge work" of a certain importance. (This is mentioned in the post a few times, but just to be clear.) There is a whole category of LLM tasks for which these constraints and insights don't apply fully or at all. For example, using AI for a quick web search or to learn what the capital of France is doesn't need the level of care and metacognitive effort I wrote about here.
- This framework applies to general-purpose LLMs, not specialized AI. In narrow domains (e.g., medical imaging, chess), specialized AI systems trained on domain-specific datasets already match or exceed human expert pattern recognition. The delegation assignments—particularly Auto-Convergent as purely human—may not hold for those systems.
- I'm not claiming that this framework covers all forms of thought. I think the three axes I adopted—the Tripartite Mind, Convergent-Divergent thought, and Object vs Meta—capture the most salient cognitive modalities for the specific question of how to interface well with an LLM. But AAT is silent about other important axes, e.g. social, emotional, embodied. I would be very interested to see an analysis of those in the same way.
- The glutamate fatigue mechanism should be held lightly. While the Wiehler et al. 22 finding remains widely cited, the specific claim that glutamate is the causal agent of cognitive fatigue is still debated. At least three candidate metabolites have been proposed 23, and the observed effect may serve a signaling purpose rather than reflect toxic buildup 83. The AAT framework relies on the robust practical consequence (sustained cognitive control degrades decision quality), not on any single metabolic mechanism.
- The DMN-ECN account of creativity is contested. The framework's escalating fatigue curve for divergent thinking rests partly on the DMN-ECN (Default Mode Network - Executive Control Network) switching model 28, which has been challenged on methodological and interpretive grounds 84. The practical observation—divergent thinking gets harder within a session—seems to hold regardless.
- Note on algorithmic fatigue variability. The "medium, then high" rating for algorithmic categories assumes novel procedures with high element interactivity—multiple interdependent elements held in working memory simultaneously 3132. Practiced algorithmic work with low element interactivity (e.g., routine algebra and old-school assembly line work) lets you internalize the patterns and execute them as near-autonomous steps 85 requiring minimal prefrontal engagement per step. Such work is slow but not prefrontally fatiguing. This distinction matters for the time savings argument: the algorithmic work LLMs replace most dramatically is often precisely this low-intensity kind, meaning the "metabolic breaks" it inadvertently provided also disappear.
- LLM capabilities are a moving target. The delegation assignments reflect 2026-era general-purpose LLMs. As models improve—particularly in meta-reflective ⓘ support (though current LLM metacognition still diverges from human metacognition in important ways 86)—some "Human-only" categories may shift toward "Joint Human&LLM." The framework's structure (the grid itself) should outlast any particular assignment.
References
Footnotes
-
Brynjolfsson, E., Li, D., & Raymond, L. R. (2025). Generative AI at work. The Quarterly Journal of Economics, 140(2), 889–942. https://doi.org/10.1093/qje/qjae044. ↩ ↩2
-
Rogelberg, S. (2026). Thousands of CEOs admit AI had no impact on employment or productivity—and it has economists resurrecting a paradox from 40 years ago. Fortune. https://fortune.com/article/why-do-thousands-of-ceos-believe-ai-not-having-impact-productivity-employment-study/. ↩
-
Michalski, J., Winters, S., Gunn, D., Holland, J., (2025). AI ROI: The paradox of rising investment and elusive returns. Deloitte Research. https://www.deloitte.com/global/en/issues/generative-ai/ai-roi-the-paradox-of-rising-investment-and-elusive-returns.html. ↩
-
Faros Research. (2025). The AI Productivity Paradox Report 2025. Faros. https://www.faros.ai/blog/ai-software-engineering. ↩
-
Gruda, D., & Aeon, B. (2025). Seven myths about AI and productivity: What the evidence really says. California Management Review, 68(2). https://cmr.berkeley.edu/2025/10/seven-myths-about-ai-and-productivity-what-the-evidence-really-says/. ↩ ↩2
-
Stadler, M., Bannert, M., & Sailer, M. (2024). Cognitive ease at a cost: LLMs reduce mental effort but compromise depth in student scientific inquiry. Computers in Human Behavior, 160, 108386. https://doi.org/10.1016/j.chb.2024.108386. ↩
-
Lee, H.-P. (Hank), Sarkar, A., Tankelevitch, L., Drosos, I., Rintel, S., Banks, R., & Wilson, N. (2025). The Impact of Generative AI on Critical Thinking: Self-Reported Reductions in Cognitive Effort and Confidence Effects From a Survey of Knowledge Workers. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI '25), Article 1121, 1–22. https://doi.org/10.1145/3706598.3713778. ↩ ↩2
-
Kosmyna, N., Hauptmann, E., Yuan, Y. T., Situ, J., Liao, X.-H., Beresnitzky, A. V., Braunstein, I., & Maes, P. (2025). Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task. arXiv:2506.08872. https://arxiv.org/abs/2506.08872. ↩
-
Kabashkin, I. (2025). Cognitive Atrophy Paradox of AI–Human Interaction: From Cognitive Growth and Atrophy to Balance. Information, 16(11), 1009. https://www.mdpi.com/2078-2489/16/11/1009. ↩ ↩2
-
Mineo, L. (2025). Is AI dulling our minds? Harvard Gazette. https://news.harvard.edu/gazette/story/2025/11/is-ai-dulling-our-minds/. ↩ ↩2
-
El Tarhouny, S., & Farghaly, A. (2026). Deskilling Dilemma: Brain Over Automation. Frontiers in Medicine. https://www.frontiersin.org/journals/medicine/articles/10.3389/fmed.2026.1765692/full. ↩ ↩2
-
Tankelevitch, L., Kewenig, V., Simkute, A., Scott, A. E., Sarkar, A., Sellen, A., & Rintel, S. (2024). The Metacognitive Demands and Opportunities of Generative AI. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, Article 680, 1–24. https://doi.org/10.1145/3613904.3642902. ↩ ↩2 ↩3
-
Stanovich, K. E. (2010). Rationality and the Reflective Mind. Oxford University Press. ↩
-
Nelson, T. O., & Narens, L. (1990). Metamemory: A theoretical framework and new findings. Psychology of Learning and Motivation, 26, 125–173. ↩
-
Guilford, J. P. (1967). The Nature of Human Intelligence. McGraw-Hill. ↩
-
Lawson, B. (2005). How Designers Think (4th ed.). Architectural Press. ↩
-
Cross, N. (2011). Design Thinking: Understanding How Designers Think and Work. Berg. ↩
-
Bartoli, E., et al. (2024). Default mode network electrophysiological dynamics and causal role in creative thinking. Brain, 147(10), 3409–3425. https://doi.org/10.1093/brain/awae199. ↩
-
Lopez-Lopez, E., Abels, C. M., Lorenz-Spreen, P., Lewandowsky, S., & Herzog, S. M. (2026). Boosting metacognition in entangled human-AI interaction to navigate cognitive-behavioral drift. arXiv:2602.01959. https://arxiv.org/abs/2602.01959. ↩ ↩2
-
Simon, H. A. (1969). The Sciences of the Artificial. MIT Press. ↩
-
Wikipedia (2026). Cognitive miser. https://en.wikipedia.org/wiki/Cognitive_miser. ↩ ↩2
-
Wiehler, A., Branzoli, F., Adanyeguh, I., Mochel, F., & Pessiglione, M. (2022). A neuro-metabolic account of why daylong cognitive work alters the control of economic decisions. Current Biology, 32(16), 3564–3575. https://doi.org/10.1016/j.cub.2022.07.010. ↩ ↩2 ↩3
-
André, N., et al. (2025). Brain Endurance Training as a Strategy for Reducing Mental Fatigue. Frontiers in Psychology. https://www.frontiersin.org/journals/psychology/articles/10.3389/fpsyg.2025.1616171/full. ↩ ↩2
-
Steward, G., et al. (2025). The Neurobiology of Cognitive Fatigue and Its Influence on Effort-Based Choice. Journal of Neuroscience. https://www.jneurosci.org/content/jneuro/early/2025/05/08/JNEUROSCI.1612-24.2025.full.pdf. ↩ ↩2
-
Xu, X., et al. (2014). Failure to replicate depletion of self-control. PLOS ONE, 9(10), e109950. https://doi.org/10.1371/journal.pone.0109950. ↩
-
Weber, S., et al. (2022). Involvement of the default mode network under varying levels of cognitive effort. Scientific Reports, 12, 6303. https://doi.org/10.1038/s41598-022-10289-7. ↩
-
Buckner, R. L., Andrews-Hanna, J. R., & Schacter, D. L. (2008). The brain's default network: Anatomy, function, and relevance to disease. Annals of the New York Academy of Sciences, 1124(1), 1–38. https://doi.org/10.1196/annals.1440.011. ↩
-
Chen, Q., et al. (2025). Dynamic switching between brain networks predicts creative ability. Communications Biology, 8, 54. https://doi.org/10.1038/s42003-025-07470-9. ↩ ↩2
-
Petruo, V. A., et al. (2018). On the role of the prefrontal cortex in fatigue effects on cognitive flexibility — a system neurophysiological approach. Scientific Reports, 8, 6395. https://doi.org/10.1038/s41598-018-24834-w. ↩
-
Beaty, R. E., et al. (2015). Default and executive network coupling supports creative idea production. Scientific Reports, 5, 10964. https://www.nature.com/articles/srep10964. ↩
-
Sweller, J. (1994). Cognitive load theory, learning difficulty, and instructional design. Learning and Instruction, 4(4) https://doi.org/10.1016/0959-4752(94)90003-5. ↩ ↩2
-
Sweller, J. (2010). Element Interactivity and Intrinsic, Extraneous, and Germane Cognitive Load. Educational Psychology Review, 22, 123-138 https://doi.org/10.1007/s10648-010-9128-5. ↩ ↩2
-
Fleming, S. M., Huijgen, J., & Dolan, R. J. (2012). Prefrontal contributions to metacognition in perceptual decision making. The Journal of neuroscience : the official journal of the Society for Neuroscience, 32(18), 6117–6125. https://doi.org/10.1523/JNEUROSCI.6489-11.2012. ↩
-
Balconi, M., Acconito, C., Allegretta, R. A., & Crivelli, D. (2023). What Is the Relationship between Metacognition and Mental Effort in Executive Functions? The Contribution of Neurophysiology. Behavioral sciences (Basel, Switzerland), 13(11), 918. https://doi.org/10.3390/bs13110918. ↩
-
Microsoft Research. (2025). The future of AI in knowledge work: Tools for thought at CHI 2025. https://www.microsoft.com/en-us/research/blog/the-future-of-ai-in-knowledge-work-tools-for-thought-at-chi-2025/. ↩
-
Papadopetraki, D., et al. (2025). Shielding working memory from distraction is more effortful than flexible updating. Scientific Reports, 15, 13512. https://doi.org/10.1038/s41598-025-96980-x. ↩
-
Petrusic, W. M., & Baranski, J. V. (2003). Judging confidence influences decision processing in comparative judgments. Psychonomic bulletin & review, 10(1), 177–183. https://doi.org/10.3758/bf03196482. ↩
-
Jordano, M. L., & Touron, D. R. (2018). How often are thoughts metacognitive? Findings from research on self-regulated learning, think-aloud protocols, and mind-wandering. Psychon Bull Rev, 25, 1269–1286. https://doi.org/10.3758/s13423-018-1490-1. ↩
-
Fukumura, K., & Ito, T. (2025). Can LLM-Powered Multi-Agent Systems Augment Human Creativity? Evidence from Brainstorming Tasks. https://dl.acm.org/doi/10.1145/3715928.3737479. ↩
-
Osmani, A. (Substack, 2026). Code review in the age of AI. https://addyo.substack.com/p/code-review-in-the-age-of-ai. ↩
-
Huang, J., Chen, X., Mishra, S., Zheng, H. S., Yu, A. W., Song, X., & Zhou, D. (2024). Large Language Models Cannot Self-Correct Reasoning Yet. Proceedings of the International Conference on Learning Representations (ICLR 2024). https://arxiv.org/abs/2310.01798. ↩ ↩2
-
Madaan, A., Tandon, N., Gupta, P., et al. (2023). Self-Refine: Iterative Refinement with Self-Feedback. Advances in Neural Information Processing Systems 36 (NeurIPS 2023). https://arxiv.org/abs/2303.17651. ↩ ↩2
-
De Freitas, J., et al. (2025). Research: When used correctly, LLMs can unlock more creative ideas. Harvard Business Review. https://hbr.org/2025/12/research-when-used-correctly-llms-can-unlock-more-creative-ideas. ↩
-
Doshi, A. R., & Hauser, O. P. (2024). Generative AI enhances individual creativity but reduces the collective diversity of novel content. Science Advances, 10(28). https://www.science.org/doi/10.1126/sciadv.adn5290. ↩
-
Sourati, Z., Ziabari, A. S., & Dehghani, M. (2026). The homogenizing effect of large language models on human expression and thought. Trends in Cognitive Sciences. https://doi.org/10.1016/j.tics.2026.01.003. ↩
-
Qin, P., et al. (2025). Timing Matters: How Using LLMs at Different Timings Influences Writers' Perceptions and Ideation Outcomes in AI-Assisted Ideation. https://dl.acm.org/doi/10.1145/3706598.3713146. ↩
-
Shin, J., et al. (2025). No Evidence for LLMs Being Useful in Problem Reframing (CHI '25). Association for Computing Machinery, New York, NY, USA, Article 243, 1–25. https://doi.org/10.1145/3706598.3713273. ↩ ↩2
-
Holstein, J., Diener, M., & Spitzer, P. (2025). From Consumption to Collaboration: Measuring Interaction Patterns to Augment Human Cognition in Open-Ended Tasks. arXiv:2504.02780. https://arxiv.org/abs/2504.02780. ↩
-
Barcaui, A. (2025). ChatGPT as a cognitive crutch: Evidence from a randomized controlled trial on knowledge retention. Social Sciences & Humanities Open, 12, 102287. https://doi.org/10.1016/j.ssaho.2025.102287. ↩
-
Lane, J. N., et al. (2025). The Narrative AI Advantage? A Field Experiment on AI-Augmented Evaluations of Early-Stage Innovations. Harvard Business School Working Paper, 25-001. https://www.hbs.edu/ris/Publication%20Files/25-001_8ebbe0cb-2a19-453c-9014-1e301e8dd2fb.pdf. ↩ ↩2 ↩3
-
Kahana, E. (2026). Built by agents, tested by agents, trusted by whom? Stanford CodeX. https://law.stanford.edu/2026/02/08/built-by-agents-tested-by-agents-trusted-by-whom/. ↩
-
Garg, R. (2026). Design-first collaboration: Reducing friction with AI. Thoughtworks / martinfowler.com. https://martinfowler.com/articles/reduce-friction-ai/design-first-collaboration.html. ↩
-
Osmani, A. (2026). My LLM coding workflow going into 2026. https://addyosmani.com/blog/ai-coding-workflow/. ↩
-
Willison, S. (n.d.). AI-assisted programming posts. simonwillison.net. https://simonwillison.net/tags/ai-assisted-programming/. ↩
-
Sun, W., & Liu, J. (2025). The Impact of Human-AI Interaction Patterns on Problem Solving, AI Literacy, and Metacognition. Proceedings of the 6th International Conference on AI Research (ICAIR 2025), 6(1). https://doi.org/10.34190/icair.5.1.4276. ↩
-
Lewis, P. A., Birch, A., Hall, A., & Dunbar, R. I. M. (2017). Higher order intentionality tasks are cognitively more demanding. Social Cognitive and Affective Neuroscience, 12(7), 1063–1071. https://doi.org/10.1093/scan/nsx034. ↩
-
Becker, S., Rush, J., et al. (METR). (2025). Measuring the impact of early-2025 AI on experienced open-source developer productivity. arXiv:2507.09089. https://arxiv.org/abs/2507.09089. ↩ ↩2
-
Asay, M. (2025). AI's trust tax for developers. InfoWorld. https://www.infoworld.com/article/4111829/ais-trust-tax-for-developers.html. ↩
-
Bick, A., et al. (2025). The Impact of Generative AI on Work Productivity. Federal Reserve Bank of St. Louis. https://www.stlouisfed.org/on-the-economy/2025/feb/impact-generative-ai-work-productivity. ↩
-
Jiang, W., et al. (2025). As AI's power grows, so does our workday. CEPR VoxEU. https://cepr.org/voxeu/columns/ais-power-grows-so-does-our-workday. ↩
-
Ranganathan, A., & Ye, X. M. (2026). AI doesn't reduce work — it intensifies it. Harvard Business Review. https://hbr.org/2026/02/ai-doesnt-reduce-work-it-intensifies-it. ↩ ↩2 ↩3
-
Menlo Ventures. (2025). 2025: The State of Generative AI in the Enterprise. https://menlovc.com/perspective/2025-the-state-of-generative-ai-in-the-enterprise/. ↩
-
Anthropic. (2026). Anthropic Economic Index report: Economic primitives. https://www.anthropic.com/research/anthropic-economic-index-january-2026-report. ↩
-
Shalu, V. N., et al. (2025). The Cognitive Cost of AI: How AI Anxiety and Attitudes Influence Decision Fatigue in Daily Technology Use. Ann Neurosci. https://doi.org/10.1177/09727531251359872 ↩
-
Gerlich, M. (2025). From Offloading to Engagement: An Experimental Study on Structured Prompting and Critical Reasoning with Generative AI. Data, 10(11), 172. https://doi.org/10.3390/data10110172. ↩
-
Bedard, J., Kropp, M., Hsu, M., Karaman, O. T., Hawes, J., & Rosen Kellerman, G. (2026). When Using AI Leads to "Brain Fry." Harvard Business Review. https://hbr.org/2026/03/when-using-ai-leads-to-brain-fry. ↩
-
Hermann, E., Puntoni, S., & Morewedge, C. K. (2026). Why Gen AI Feels So Threatening to Workers. Harvard Business Review. https://hbr.org/2026/03/why-gen-ai-feels-so-threatening-to-workers. ↩
-
Khan, S. M. F. A., & Suhluli, S. (2025). Generative AI and Cognitive Challenges in Research: Balancing Cognitive Load, Fatigue, and Human Resilience. Technologies, 13(11), 486. https://www.mdpi.com/2227-7080/13/11/486. ↩
-
Gobet, F., & Simon, H. A. (1998). Expert chess memory: Revisiting the chunking hypothesis. Memory, 6(3), 225–255. https://doi.org/10.1080/741942359. ↩
-
Dreyfus, S. E. (2004). The five-stage model of adult skill acquisition. Bulletin of Science, Technology & Society, 24(3), 177–181. https://doi.org/10.1177/0270467604264992. ↩
-
Chase, W. G., & Simon, H. A. (1973). Perception in chess. Cognitive Psychology, 4(1), 55–81. https://doi.org/10.1016/0010-0285(73)90004-2. ↩
-
Glenberg, A. M., & Epstein, W. (1987). Inexpert calibration of comprehension. Memory & Cognition, 15(1), 84–93. https://doi.org/10.3758/BF03197714. ↩
-
Oskamp, S. (1965). Overconfidence in case-study judgments. Journal of Consulting Psychology, 29(3), 261–265. https://doi.org/10.1037/h0022125. ↩
-
McKenzie, C. R. M., Liersch, M. J., & Yaniv, I. (2008). Overconfidence in interval estimates: What does expertise buy you? Organizational Behavior and Human Decision Processes, 107(2), 179–191. https://doi.org/10.1016/j.obhdp.2008.02.003. ↩
-
Dane, E. (2010). Reconsidering the trade-off between expertise and flexibility: A cognitive entrenchment perspective. Academy of Management Review, 35(4), 579–603. https://doi.org/10.5465/amr.35.4.zok579. ↩
-
Bilalić, M., McLeod, P., & Gobet, F. (2008). Why good thoughts block better ones: The mechanism of the pernicious Einstellung (set) effect. Cognition, 108(3), 652–661. https://doi.org/10.1016/j.cognition.2008.05.005. ↩
-
Englich, B., Mussweiler, T., & Strack, F. (2006). Playing dice with criminal sentences: The influence of irrelevant anchors on experts' judicial decision making. Personality and Social Psychology Bulletin, 32(2), 188–200. https://doi.org/10.1177/0146167205282152. ↩
-
Liu, G., Christian, B., Dumbalska, T., Bakker, M. A., & Dubey, R. (2026). AI Assistance Reduces Persistence and Hurts Independent Performance. arXiv:2604.04721. https://arxiv.org/abs/2604.04721. ↩
-
Ferdman, A. (2025). AI deskilling is a structural problem. AI & Society, 41(4). https://doi.org/10.1007/s00146-025-02686-z. ↩
-
Noy, S., & Zhang, W. (2023). Experimental evidence on the productivity effects of generative artificial intelligence. Science, 381(6654), 187–192. https://doi.org/10.1126/science.adh2586. ↩
-
Dell'Acqua, F., McFowland, E., III, Mollick, E., Lifshitz-Assaf, H., Kellogg, K. C., Rajendran, S., Krayer, L., Candelon, F., & Lakhani, K. R. (2023). Navigating the jagged technological frontier: Field experimental evidence of the effects of AI on knowledge worker productivity and quality. Harvard Business School Working Paper 24-013. https://www.hbs.edu/faculty/Pages/item.aspx?num=64700. ↩
-
Duncan, D. S. (2026). How do workers develop good judgment in the AI era? Harvard Business Review. https://hbr.org/2026/02/how-do-workers-develop-good-judgment-in-the-ai-era. ↩
-
Underwood, E. (2022). Mentally exhausted? Study blames buildup of key chemical in brain. Science, https://doi.org/10.1126/science.ade3733. ↩
-
Abraham, A. (2025). Occam's Razor Misapplied: Pinpointing the Role of the Default Mode Network in Creativity. Current Opinion in Behavioral Sciences. https://www.sciencedirect.com/science/article/abs/pii/S2352154625001032. ↩
-
Anderson, J. R. (1982). Acquisition of cognitive skill. Psychological Review, 89(4), 369–406. https://doi.org/10.1037/0033-295X.89.4.369. ↩
-
Steyvers, M., & Peters, M. A. K. (2025). Metacognition and Uncertainty Communication in Humans and Large Language Models. Current Directions in Psychological Science, 0(0). https://journals.sagepub.com/doi/10.1177/09637214251391158. ↩
Cover image:
Modified from Diehl's Anatomy for artists and students Pl.3, Conrad Diehl
 AIFramings and ModelsMind
AIFramings and ModelsMind
Comments
Loading comments...